AI T-Rex game: Machine Learning (Neural Network and Genetic Algorithm)
Introduction
The purpose of this article is to give you an introduction on artificial intelligence, by discovering in particular two algorithms that are widely used in the field. No need to have previous knowledge of AI to understand this article, nor of programming: maybe just a little technical or mathematical mind. I will voluntarily simplify some explanations of these algorithms, which can sometimes quickly become complex. The main interest is to show you how they work in general, so that you will no longer be lost when you hear something about machine learning, a field that is increasingly being used nowadays.
I think the best way to explain it to you is through concrete examples of use. I will explain you how I made an artificial intelligence to play the game T-Rex.
T-Rex is a game integrated on the Google Chrome browser, which appears when you do not have internet. The goal is simple, you control a dinosaur, which advances alone, and where you must avoid the obstacles that appear by jumping. If you have never seen this game before, I strongly advise you to try it a little bit before going any further, by going to this link, or by typing chrome://dino/ in your address bar (Google Chrome only).
The idea of this AI that we are going to create is to learn to play by watching my own games. I am going to play the game myself, and recording my decisions. The AI will have the intelligence to be able to make decisions at any time (with a Neural Network algorithm), and we will use an algorithm to make its intelligence look as close as possible to my decisions (thanks to the Genetic Algorithm). Well, that also means we have to be good at the game, if we are bad, so will the AI.
Analysis of the T-Rex game
It is pretty easy to say that we have to record our games, and say that the AI will have to be close to our decisions. What does that mean in practice?
If we think about it, our decisions about the game are pretty simple: either we jump or we do not jump (we wait).
Now, what do these decisions depend on?
It depends on the next obstacle. You have to jump when there is an obstacle, but you also have to wait before jumping to be sure to fall back after the end of the obstacle. And there are several types of them: some are high, some are long, and some are birds (so at altitude). In concrete terms, we can conclude that our decisions will depend on:
- The width of the next obstacle
- The length of the next obstacle
- The altitude of the next obstacle
- The distance between the T-Rex and the next obstacle
There is another parameter to take into account: as we progress in the game, our T-Rex moves faster and faster. When you move fast, you have to jump earlier. Our decisions will therefore also depend on our speed.
That's all we need. To summarize with a schema:
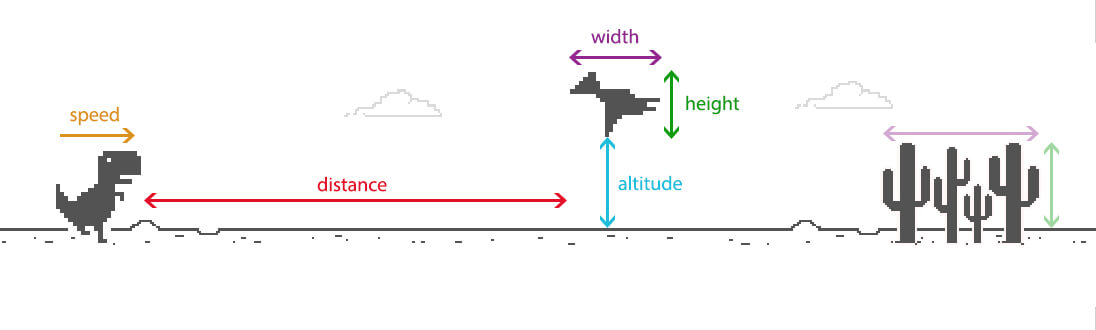
Here is what the intelligence of our AI will consist of: at any moment, we give it our 5 parameters, and it tells us if we should jump or not. And we start again a few milliseconds later, and so on, until the end of the game.
A little observation, we have two possible outputs in what I presented: we jump, or we do not jump. But it is not possible to do both at the same time (or any of them at all). We will therefore simplify into one single output: a number, which is 0 if we do not jump, or 1 if we jump.
Neural Network
Definition
What is a neural network? To put it really simple, it is like your brain. Our brain has many possible inputs (sight, memories, feelings,...), many computational neurons, which possibly generate output actions (talking, moving,...). The purpose of this algorithm is to try to have a similar behavior: to have inputs (our T-Rex parameters at a time T), intermediate steps of computations, then outputs (for our case, to know if we should jump or not).
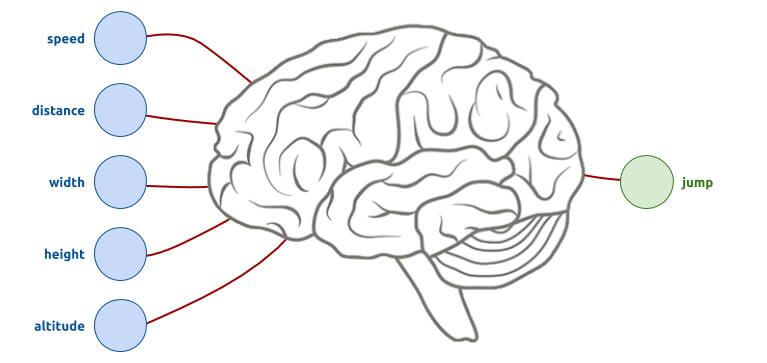
The central part is a mess of networks. All you have to do is cut the brain into several slices. Each of its slices (also called "hidden layer") is linked to the adjacent slices (including with input parameters, and output decisions). And to add a little difficulty, these links are not all similar, each one is more or less important (the more important it is, the more it will be taken into account in the decision path):
Simpler application
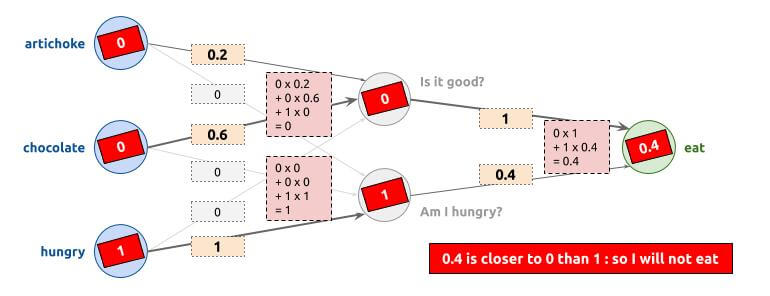
All right, it is getting a little complicated, we take a break with the T-Rex and take a simpler example to be more concrete. We are going to make another neural network, which has 3 parameters: "Do I have artichokes?", "Do I have chocolate?", "Do I feel hungry?". The output will be "Do I eat?". Well, it is not that I do not like artichokes, but I only want to eat them if I am hungry, while chocolate... All values are 0 (if no) or 1 (if yes). Here is what the neural network can looks like in this example:
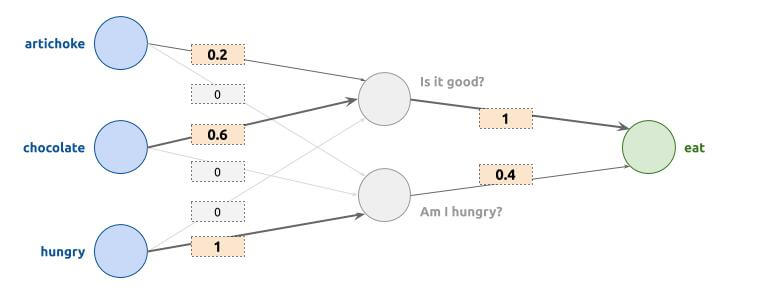
The values of each internal node must be calculated. Each node is the sum of the entries multiplied by their weight. For the 1st internal node ("Is it good?"), its value is therefore the sum of :
- The value of "artichoke" (0 or 1), multiplied by the weight of the link which is 0.2 here.
- The value of "chocolate" (0 or 1), multiplied by the weight of the link which is 0.6.
- The value of "hungry" (0 or 1), multiplied by the weight of the link which is 0. So the node "Is it good?" does not depend on this parameter.
For the 2nd internal node ("Am I hungry?"), it is simply the value of the "hungry" input, since it is the only link at 1, while the others are at 0.
Finally, the "eat" decision will therefore depends on these 2 internal nodes:
- If it is good, with a weight of 1
- If I am hungry, with a weight of 0.4
We will only eat if the output is closer to 1 than 0. We will see it in the examples below, but it allows us:
- To eat chocolate, even if we are not hungry.
- To eat artichokes only if we are hungry.
- To eat nothing if we have neither artichokes nor chocolate.
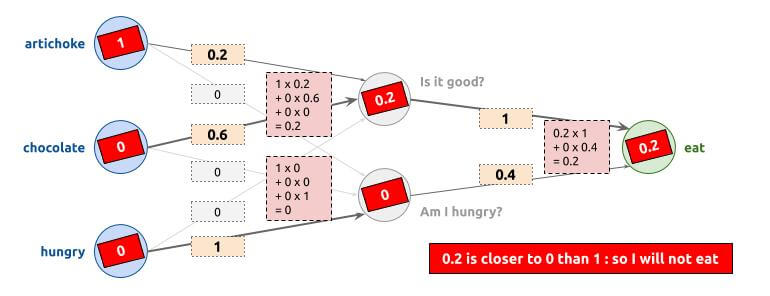
First example
Example when I have artichokes, I do not have chocolate, and I am not hungry. As a result, I am not going to eat (I will not eat artichokes for fun):
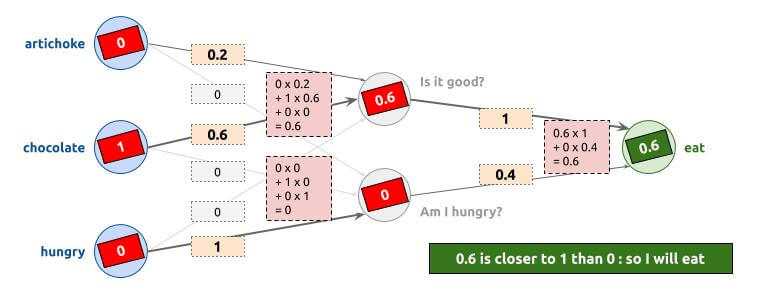
Second example
Example when I do not have artichokes, I have chocolate, and I am not hungry. As a result, I am going to eat that chocolate:
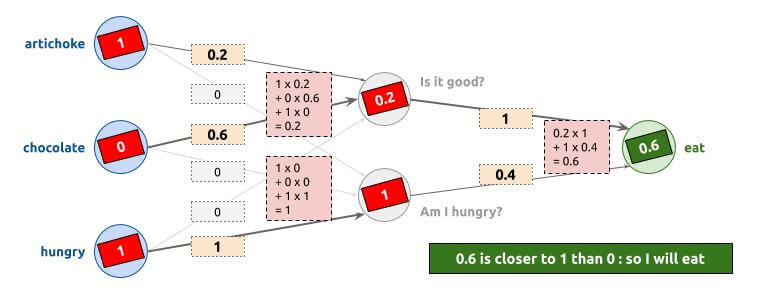
Third example
Example when I have artichokes, I do not have chocolate, and I am hungry. As a result, I am going to eat (artichokes are fine when I am hungry):
Forth example
Last example when I do not have artichokes, I do not have chocolate, but I am hungry. As a result, I am not going to eat (I have nothing to eat):
Back to our T-Rex
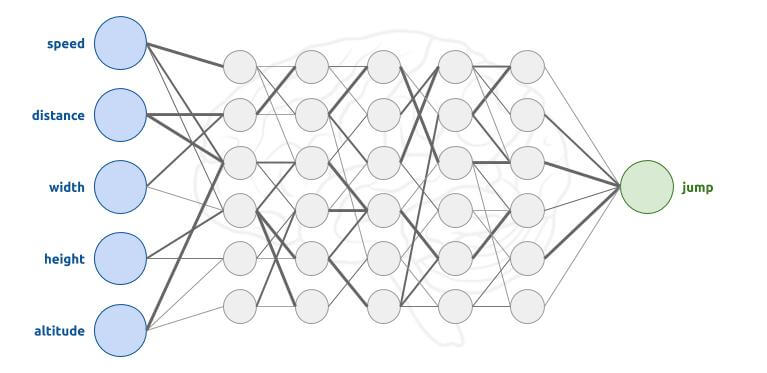
Well here, the number of layers, the number of nodes, the weights to define, we can do them ourselves (this is even what I did for this example). But when we arrive with more complex applications (5 parameters like T-Rex, with speeds to calculate,...), we can no longer define our network ourselves. And our case of the T-Rex has only 5 parameters and only one output, for some applications, there can be hundreds of inputs and as many outputs. And the more inputs we have, the more hidden layers and nodes we will probably need.
And the more hidden layers there are, the more accurate the AI will be able to make decisions, but the longer it will take to calculate. You have to find the right balance, and it is not always easy to decide. For our T-Rex application I chose to have 5 hidden layers, each composed of 6 nodes (I changed several times, I increased until the result was better).
Then our T-Rex Neural Network look like this:
But we will now have to define the weight of each of these links. And there are so many of them that I do not want to do it by hand (and that would be much too complicated as well). This is going to be our next step. I hope you have a good understanding of how the neural network works.
Records of my games
The purpose of this article is to present the AI methods I have used. So I am going to move on quickly to this section.
To be able to record my games, or use AI on this game, I had to modify the game a little bit, to get the settings (speed, obstacle, ...), to know when I jumped, or to indicate that I want to jump when the AI tells me. The source code of the T-Rex game is available here if you want.
So I recorded several of my games. I only kept the parts I was not too bad at. And when I lost, I deleted my last decisions (since they were necessarily bad). We finally get a huge file that contains all my decisions (3203 decisions to be more precise). Here is a sample of them:
| Speed | Distance | Width | Height | Altitude | Jump |
|---|---|---|---|---|---|
| 6.54 | 374 | 51 | 35 | 0 | No |
| 7.59 | 99 | 34 | 35 | 0 | Yes |
| 8.88 | 146 | 46 | 40 | 1 | No |
| 9.71 | 406 | 17 | 35 | 0 | No |
| 10.55 | 449 | 46 | 40 | 0 | No |
| 11.22 | 370 | 34 | 35 | 0 | No |
| 12.51 | 101 | 51 | 35 | 0 | Yes |
| 13.00 | 277 | 17 | 35 | 0 | No |
Genetic Algorithm (GA)
Our goal now will be to set all the weights of our neural network. As we have seen before, these will have to be defined so that this network can take decisions as close as possible to mine. The principle is simple, it will be necessary to test many different networks, and to assign a score to each of them. This score will be given according to the number of correct decisions: for each of my recorded decisions, we try the network, and we see if it decides the same thing; if it does, it earns points.
But how do we generate all these networks? You can not create them all, there are an infinite number of them... This is where Genetic Algorithm (GA) comes in.
The purpose of this algorithm is to create what is called a population (several neural networks, all different, created randomly at the beginning). We evaluate each individual of this population (we compute a score for them, called fitness), we keep only the best ones (called selection), and we modify them a little (by mixing them, by updating some values,...) to create a new population. Then we start over: we re-evaluate each individual, we keep the best, we modify them to make a new population, and so on.
A more concrete example in real life? In fact, this algorithm is inspired by certain aspects of biological evolution:

Over the centuries, the human (the population) have evolved to be more efficient (a better fitness/score). The best are those who have lived longer, who have been able to reproduce themselves, to create a better population. The further we go in the centuries, the better the population is. Like the GA:
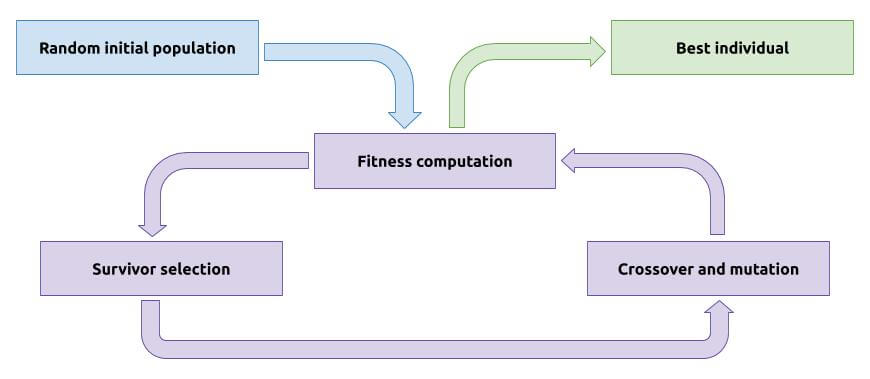
- Random initial population. We create 1000 individuals. Each of them is a neural network possible solution, composed of random values to define the weights of the links.
- We repeat until we have a network that has a pretty good score:
- Fitness computation. We compute the score for each individual. Has seen before, the score is the number of recorded decisions that have the same output (jump or not).
- Survivor selection. We keep the best half of the population.
- Crossover. There is a probability to apply a crossover operation. This consists in mixing the values between 2 individuals (by averaging each value to be simple).
- Mutation. There is a probability to apply a mutation operation. This consists in slightly modifying some of the individual's values.
The population can only improve, or at least the best individual is as good as the previous population, since we always keep the best neural network intact (even if we can create other individuals from it, thanks to crossover and mutation). Once we have done enough turns, we can extract the best individual, and use its values to complete our neural network, which should make decisions close to mine.
Conclusion, Machine learning and Unsupervised learning
After letting our GA run for a while, I exported the values. You can now see my intelligence in action on this link, or through this video:
What we just did was machine learning: a program that learned to make decisions from trained data (my previously recorded decisions).
The result is pretty nice, it works relatively well, and honestly it is cool to be able to say that the program uses my intelligence. Fortunately, I was not too bad during the recordings, that is what allowed the AI to be correct. She copied me, avoiding having my human errors when I lost (devolution, fatigue, inattention,...).
But this AI is now a little limited: it can never get better than me (if we just base it on the playing strategies). We all have our own techniques: wait until the last moment to jump, or jump as soon as it is possile for example. Worse, I may have made a mixture of the two: depending on the speed, I did not necessarily need to make perfect jumps at first when it was easy. It can mislead the AI at times.
And here the T-Rex game is relatively simple, few inputs and only one possible output. Imagine the same thing on a checkers game, poker, etc. Needless to say that the number of inputs and outputs would be much higher, but what I want to show you is that there are many more available strategies to win. And sometimes, it can even be strategies that even the best current players have not yet thought of. By learning from recordings of the world's best players, there is no guarantee that intelligence will be the best possible.
This is the moment where we are talking about unsupervised learning. The principle of this is that the AI must learn by itself. If we look back at our GA, the fitness function, rather than calculating a score based on my performance, it would be better if it played the game itself and used the game score to compare itself to other individuals in the population. At first, the intelligence would clearly suck (as monkey men were a few centuries ago, I guess). But as the turns progressed, it would become more intelligent, and above all better than any human.
Why did not I do this directly? First of all because I am still quite smart enough (just joking), but especially because it is very, very long to compute. Imagine that for each population (1000 individuals here), you have to play a game. When a solution becomes more or less interesting, it will not lose for several minutes. 1000 x 5 minutes, it would take more than 3 days to test a population. Knowing that it would be necessary to do at least 1000 turns, we are approaching the 10 years of computation. Well of course it would otherwise be necessary to update the source code of the game to make it faster during these tests, or run several score calculations in parallel too, but it is immediately more work.
One more interesting thing, for the cases of versus games (we play chess against another person/intelligence for example, it is not a solo game), it is even more complex to evaluate an individual. The method often used is to make the AI plays against itself: against its best current version.
After selling you a dream with artificial intelligence, I think it is important to note what I consider to be a big negative point in the use of neural networks. It is very powerful, this neural network manages to avoid obstacles in real time in our case, but also to recognize images of cats, recognize your family in photos, or drive an autonomous car in other cases. And all of this just through nodes, connected to each other, with weights. The whole thing is a simple mathematical operation. The problem is that it is very, very difficult to understand the decisions of our AI. When you make a program, with your own conditions, your own algorithms, you can understand and correct errors. When it is a series of numbers, it is very complicated to understand why the intelligence has chosen this decision. Here is the values used by the neural network of our T-Rex, I let you try to understand why sometimes at the very beginning of the game, our dinosaur is losing:
1 [ 2 -95.56601421853227,-85.36168246829185,5.473159957604986,-2.2524794626783855,4.720944891882393,-7.4916691544085925, 3 3.7000145778189877,40.06859910598944,53.29819896989174,-44.78287614646953,66.270631606874,-30.201819957694955, 4 78.24397239483471,-16.543948021956993,67.37003637242792,1.5497033889439737,26.561100252678365,-22.206257738432278, 5 37.585476245910534,-24.108646500703816,5.2506611682817885,22.481568269598057,-12.369921294821879,-26.53789634952111, 6 -96.61362135206807,-17.173819147522376,-122.38731979320482,26.08437453924002,6.4443673674408,-124.88919981892785, 7 10.603237872543774,-59.743113935904965,-5.817672852185882,30.60677704355442,-17.32040578223058,-6.90005628155993 8 ]
Spoiler: there is not much you can understand with these numbers. It is very complicated to debug the intelligence to understand why it makes such a decision. For this example, I have my own idea, as I said before, it is probably due to the fact that at the beginning of the game, since the dinosaur is slow, I am not constant on my jumps considering that I have time (sometimes I jump as early as possible, for others I wait until the last moment). But again... it is just an intuition. And if I want to fix it, I have no other choice to make new recordings, and start a new GA to update my neural network values.
This article was more about how machine learning can work. And there are other methods available, but neural networks are very often used. They are more complex than what I have been able to present you here, I have deliberately omitted some aspects of the algorithm to keep it simple (bias, activation functions, etc.). But do not worry, the idea of the algorithm remains the same.
You can also have what is called deep learning. We are often more intelligent if we work together as a team. Deep learning is a little bit the same, it will use several different neural networks!
I hope I have been able to help you understand some of the basics of artificial intelligence. The T-Rex was a rather simple application. I would like to go further (image processing, voice recognition,...), but the difficulty is increasing exponentially in this field, and I am far from being an expert, it quickly exceeds my current skills. A next step might be to recognize numbers on images, or better yet, the number of fingers raised with one hand on a webcam?
Source code is available on my GitHub: github.com/Dewep/T-Rex-s-neural-network.