Vector Search with AI embeddings overview
Introduction
My last technical article was few years ago, about creating an AI that plays the T-Rex game.
Although I have a MSC in Computational Intelligence, my work and my personal projects very rarely involve developing programs using artificial intelligence. But it's still a field I like to follow from afar, and try my hand at creating little POCs from time to time to discover and better understand its evolutions.
I recently saw this video of Karim Matrah, who quickly talked about using AI to better search texts in a database, thanks to embeddings and vectors search. After spending a few hours testing this topic, I thought it would be interesting to summarize its main points and give a short demonstration.
The idea is to be able to search based on the meaning of sentences, rather than having to use full-text search, which requires you to have written down the same words. For example, searching for "pets" should match articles about cats or dogs, without the word "pets" even being written in these articles.
How does it work?
Cats and dogs fall into the same category as pets. Fruit juices, wine or water are in the drinks category. But water is also in the nature category, along with mountains and forests.
Each word can be in more than one category. And each sentence is made up of several words, which together highlight certain categories, to give meaning rather than words directly.
All these texts will be represented by vectors, a list of decimal numbers, defining the meaning of the word or document. To simplify, a category will be represented by one dimension in this vector.
1 // [Animals, Home, Nature, Drinks, ...] 2 dog = [0.93, 0.72, 0.22, 0.08, ...] 3 cat = [0.95, 0.75, 0.42, 0.02, ...] 4 kitten = [0.95, 0.76, 0.45, 0.03, ...] 5 tiger = [0.91, 0.02, 0.52, 0.01, ...] 6 water = [0.33, 0.42, 0.81, 0.85, ...] 7 tree = [0.27, 0.35, 0.89, 0.07, ...]
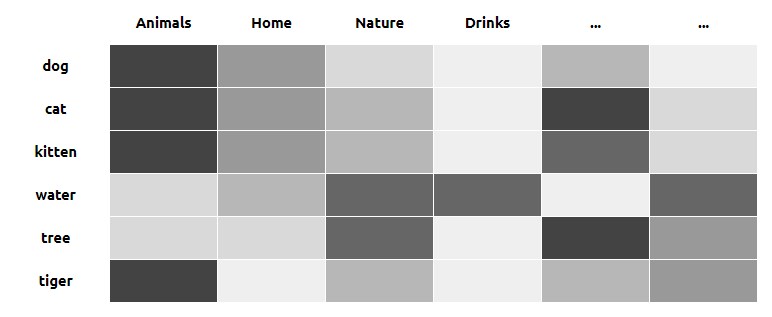
Here I've taken the example that numbers can go from 0 to 1, but these limits depend on the model used. And we won't see these limits being reached. Even if a dog is not a drink, its value is not 0, but will be close to 0. We don't drink dogs, but these 2 words remain consistent with each other (since a dog drinks). So it can be normal to have a slightly higher value compared to what a phone could have with the drink category.
To illustrate our point, we have defined these categories ourselves. But we won't need to create them: an AI model will take care of defining them for us, and finding the corresponding vector numbers for all our word groups.
Finally, when we want to query our database, we will need to compute the vector for our search, then find the vectors that are closest to what we want to find.
Sentence embeddings
There are several AI models to convert texts into vectors (known as embeddings): OpenAI API, Mistral.ai, ... But I wanted to find a local model to download, so that I would not have to depend on an external service, and keep my data private. I used the model all-MiniLM-L6-v2, which seems very well suited to my needs: local, quick to use, and low resource consumption.
Being more comfortable with NodeJS, I used the @xenova/transformers library to use this model. These few lines of code will convert texts into vectors:
1 // yarn add @xenova/transformers 2 import { pipeline } from '@xenova/transformers' 3 4 const sentence = 'My cat is used to sleeping on the bed during the day.' 5 6 // all-MiniLM-L6-v2 is a sentence-transformers model, with 384 dimensional dense vector space 7 const extractor = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2') 8 9 // pooling & normalize parameters are required for embeddings, to get vectors of fixed length 10 const output = await extractor([sentence], { pooling: 'mean', normalize: true }) 11 12 console.log(output.data) 13 // Float32Array(384) [0.09880723804235458, -0.0015220436034724116, 0.029922883957624435, ...]
A model will always produce the same vector for the same input string. On the other hand, you won't be able to understand which category a given dimension/number corresponds to: this was a simplification to better understand the idea of how it works, but this information is difficult to extract from a model.
Vector search
Now the idea is to save these embeddings in a database. We need to choose a system that can calculate vector distances. Several solutions exist: ClickHouse with cosineDistance, Postgres with pgvector, ... I'm going to use ClickHouse here, as I find it easier to work with for this demonstration:
1 $> docker run -d --name ch clickhouse/clickhouse-server 2 $> docker exec -it ch clickhouse-client
1 CREATE DATABASE search; 2 USE search; 3 4 CREATE TABLE vector_test 5 ( 6 `text` String, 7 `embeds` Array(Float32) 8 ) 9 ENGINE = MergeTree 10 ORDER BY text;
Let's add some documents, with their corresponding array of floats, generated by the model:
1 INSERT INTO vector_test (text, embeds) VALUES 2 ('I have a big house, with many rooms.', [0.14054114,0.0075286753,0.029022854,0.004870373,...]), 3 ('I am not good at swimming, unfortunately.', [0.054909922,-0.004351404,0.058526292,0.0006019556,...]), 4 ('Every morning, I take a walk in the park.', [0.067755,0.022682263,0.10086117,0.052311216,0.0734657,...]), 5 ('I have a big garden, with many vegetables.', [0.042733464,0.013591504,-0.021357052,0.011385946,...]), 6 ('I am a fan of the football team Barcelona.', [0.008374654,-0.017766343,0.041484646,-0.009141127,...]), 7 ('I have a big family, with five sisters.', [0.032610048,-0.031242535,-0.012251164,-0.040941216,...]), 8 ...
Then we can search, by computing the distance between the search embeddings and each vectors, and order them to have the top closest ones:
1 $> node embeddings.mjs "sport" 2 [-0.014155720360577106,0.07988715171813965,-0.006699294783174992,...]
1 SELECT 2 cosineDistance([-0.014155720360577106,0.07988715171813965,-0.006699294783174992,...], embeds) AS score, 3 text 4 FROM vector_test 5 ORDER BY score ASC 6 LIMIT 3
| Score | Search "sport" |
|---|---|
| 0.44 | My favorite sport is soccer, always exciting. |
| 0.56 | I like to play tennis, I played multiple tournaments. |
| 0.61 | I love to play video games, especially strategy ones. |
| Score | Search "outside" |
|---|---|
| 0.58 | The weather is nice today, really sunny. |
| 0.66 | Every morning, I take a walk in the park. |
| 0.75 | I like to travel, especially to the beach. |
| Score | Search "kittens and puppies" |
|---|---|
| 0.64 | Some cats are playing in my flat. |
| 0.69 | I would like one day to have a dog, a pomsky. |
| 0.7 | I have a pet rabbit, his name is Fluffy. |
The technical details of this part are available on the GitHub repository.
Larger example
The examples above are good for understanding how vector search works, and make it easy to check the results. But I wanted to go a step further, by giving more content to search. And most importantly, the search does not have to be based on such small sentences. It's possible to give much broader data, and search for the overall meaning of the text.
I used a dataset of songs, where the lyrics are available. The idea is to be able to search for musics based on what the lyrics mean. The way it works is totally similar to what we have seen before: we calculate a vector for each song based on their full lyrics, store them in our database, and then find the closest vector according to what we are looking for.
After adding to my ClickHouse the embeddings of 1k random songs, here is the recommended song for my search "traveling to space, to find a new place": Exodus - Boney M.. Not a single word of my query is present in the song's lyrics... but that's exactly the meaning of the story narrated in this music!
1 $> node search.mjs "traveling to space, to find a new place" | docker exec -i ch clickhouse-client --multiline --multiquery 2 Exodus - Boney M.
1 Get on board our Silver Sun 2 This is Noah's Arc 3 In the year 2001 4 Up in heaven's park. 5 6 Exodus, we go to another world. 7 Exodus, foundation a better world. 8 9 Journey of discovery. 10 From this world of ours. 11 Flying to a new home in the stars. 12 13 ...
The full lyrics are available on genius.com. The technical details of this part are available on the GitHub repository.
Conclusion
I think we can go even further: try out other AI models, try out even larger texts, try out images or other documents rather than just text, try out other databases, etc. But that's beyond the scope of this POC. I don't have any concrete projects where I could use this kind of search at the moment, so I was more interested in testing this system, and letting you discover it!